Each generation is called upon to follow its own quest.
Etienne Navarre– Ladyhawke (1985) Image from onebauer.media
Introduction
FIWARE is an open source initiative defining a universal set of standards for context data management which facilitate the development of Smart Solutions for different domains such as Smart Cities, Smart Industry, Smart Agrifood, and Smart Energy [1].
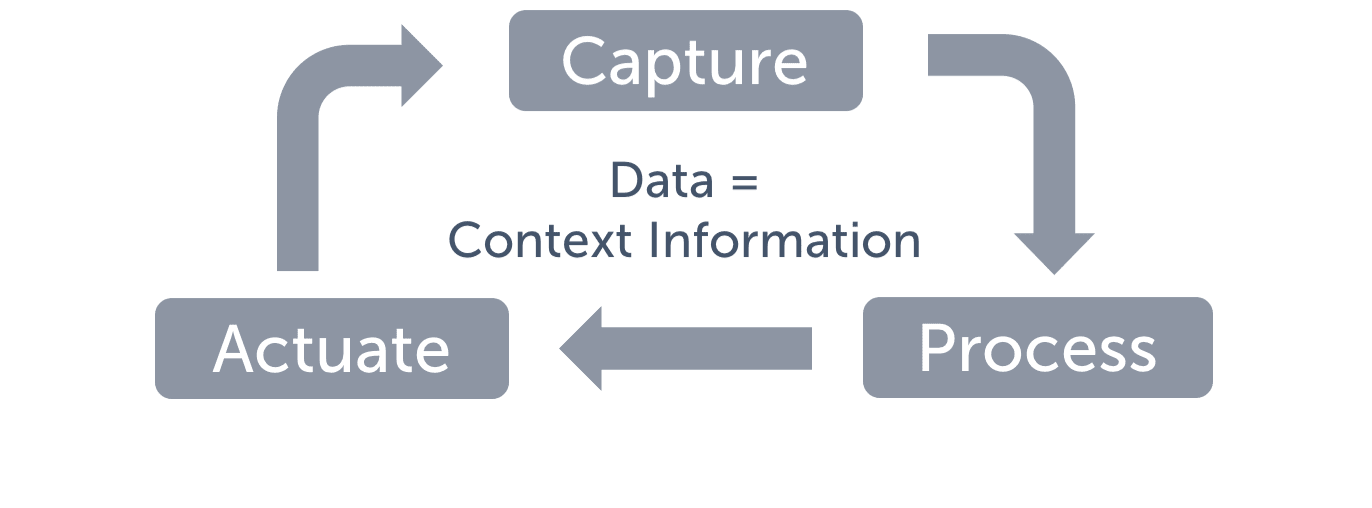
In any smart solution there is a need to gather and manage context information, processing that information and informing external actors, enabling them to actuate and therefore alter or enrich the current context. The FIWARE Context Broker component is the core component. It enables the system to perform updates and access to the current state of context [1].
The Context Broker in turn is surrounded by a suite of additional platform components, which may be supplying context data (from diverse sources such as a CRM system, social networks, mobile apps or IoT sensors for example), supporting processing, analysis and visualization of data or bringing support to data access control, publication or monetization [1].
What is context information?
Initially we will describe at how researchers have attempted to define context in the past. While most people tacitly understand what context is, they find it hard to elucidate. Previous definitions of context are done by enumeration of examples or by choosing synonyms for context [2].
In the work that first introduces the term ‘context-aware,’ Schilit and Theimer refer to context as location, identities of nearby people and objects, and changes to those objects. These types of definitions that define context by example are difficult to apply. When we want to determine whether a type of information not listed in the definition is context or not, it is not clear how we can use the definition to solve the dilemma [2].
Other definitions have simply provided synonyms for context; for example, referring to context as the environment or situation. As with the definitions by example, definitions that simply use synonyms for context are extremely difficult to apply in practice [2].
The definitions by Schilit et al. and Pascoe are closest in spirit to the operational definition we desire. Schilit claims that the important aspects of context are: where you are, who you are with, and what resources are nearby.
Pascoe defines context to be the subset of physical and conceptual states of interest to a particular entity. These definitions are too specific. Context is all about the whole situation relevant to an application and its set of users. We cannot enumerate which aspects of all situations are important, as this will change from situation to situation [2].
Anind K. Dey provides the following definition:
Context is any information that can be used to characterize the situation of an entity. An entity is a person, place, or object that is considered relevant to the interaction between a user and an application, including the user and applications themselves [2].
Anind K. Dey
If a piece of information can be used to characterize the situation of a participant in an interaction, then that information is context [2].
Take the canonical context-aware application, an indoor mobile tour guide, as an example. The obvious entities in this example are the user, the application and the tour sites. We will look at two pieces of information – weather and the presence of other people – and use the definition to determine whether either one is context [2].
The weather does not affect the application because it is being used indoors. Therefore, it is not context. The presence of other people, however, can be used to characterize the user’s situation. If a user is traveling with other people, then the sites they visit may be of particular interest to her. Therefore, the presence of other people is context because it can be used to characterize the user’s situation [2].
Context aware computing
Context-aware computing was first discussed by Schilit and Theimer in 1994 to be software that adapts according to its location of use, the collection of nearby people and objects, as well as changes to those objects over time [2].
Anind K. Dey provides the following definition for context aware computing:
A system is context-aware if it uses context to provide relevant information and/or services to the user, where relevancy depends on the user’s task.
Anind K. Dey
Similar to the problem of defining context-aware, researchers have also tried to specify the important features of a context-aware application. Again, these features have tended to be too specific to particular applications [2].
The categorization combines the ideas from previous taxonomies and attempts to generalize them to satisfy all existing context-aware applications. There are three categories of features that a context-aware application can support [2]:
presentation of information and services to a user
automatic execution of a service for a user
tagging of context to information to support later retrieval
Features of a context aware app
It encapsulates changes and the impact of changes, so applications do not need to be modified. A context related functionality is responsible for acquiring a certain type of context information and it makes that information available to the rest of the system in a generic manner, regardless of how it is actually sensed [2].
An example is interpreting context from all the devices in a conference room to determine that a meeting is occurring. For example, an indoor infrared positioning system may consist of many infrared emitters and detectors in a building. The sensors must be physically distributed and cannot all be directly connected to a single machine [2].
Context aggregators aggregate context. We defined context as information used to characterized the situation of an entity. A context aggregator, is responsible for all the context for a single entity. Aggregators gather the context about an entity (e.g., a person), behaving as a proxy for other applications [2].
What is NGSI?
The FIWARE NGSI (Next Generation Service Interface) API defines:
a data model for context information, based on a simple information model using the notion of context entities [3]
a context data interface for exchanging information by means of query, subscription, and update operations [3]
a context availability interface for exchanging information on how to obtain context information (whether to separate the two interfaces is currently under discussion) [3]
Context entities, are the center of gravity in the FIWARE NGSI information model. An entity represents a thing, i.e., any physical or logical object (e.g., a sensor, a person, a room, an issue in a ticketing system, etc.). Each entity has an entity id. Furthermore, the type system of FIWARE NGSI enables entities to have an entity type. Entity types are semantic types; they are intended to describe the type of thing represented by the entity. For example, a context entity with id sensor-365 could have the type temperatureSensor. Each entity is uniquely identified by the combination of its id and type [3].
Context attributes are properties of context entities. For example, the current speed of a car could be modeled as attribute current_speed of entity car-104.In the NGSI data model, attributes have an attribute name, an attribute type, an attribute value and metadata.
The attribute name describes what kind of property the attribute value represents of the entity, for example current_speed [3]
The attribute type represents the NGSI value type of the attribute value. Note that FIWARE NGSI has its own type system for attribute values, so NGSI value types are not the same as JSON types [3]
The attribute value finally contains
the actual data
optional metadata describing properties of the attribute value like e.g. accuracy, provider, or a timestamp [3]
The API response payloads in this specification are based on application/json and (for attribute value type operation) text/plain MIME types. Clients issuing HTTP requests with accept types different than those will get a 406 Not Acceptable error.
What is a (Orion context) broker?
A message broker is an architectural pattern for message validation, transformation, and routing. It mediates communication among applications, minimizing the mutual awareness that applications should have of each other in order to be able to exchange messages, effectively implementing decoupling.[4]
The primary purpose of a broker is to take incoming messages from applications and perform some action on them. Message brokers can decouple end-points, meet specific non-functional requirements, and facilitate reuse of intermediary functions. For example, a message broker may be used to manage a workload queue or message queue for multiple receivers, providing reliable storage, guaranteed message delivery and perhaps transaction management. The following represent other examples of actions that might be handled by the broker [4]:
Route messages to one or more destinations
Transform messages to an alternative representation
Perform message aggregation, decomposing messages into multiple messages and sending them to their destination, then recomposing the responses into one message to return to the user
Interact with an external repository to augment a message or store it
Invoke web services to retrieve data
Respond to events or errors
Provide content and topic-based message routing using the publish–subscribe pattern
Message brokers are generally based on one of two fundamental architectures: hub-and-spoke and message bus. In the first, a central server acts as the mechanism that provides integration services, whereas with the latter, the message broker is a communication backbone or distributed service that acts on the bus. Additionally, a more scalable multi-hub approach can be used to integrate multiple brokers [4] .
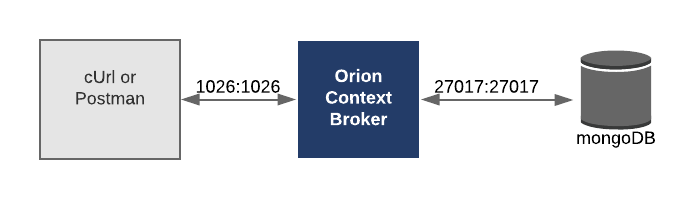
So, Orion is a C++ implementation of the NGSIv2 REST API binding developed as a part of the FIWARE platform. The Orion context broker allows us to manage the entire lifecycle of context information including updates, queries, registrations and subscriptions. Using the Orion Context Broker, you are able to create context elements and manage them through updates and queries. In addition, you can subscribe to context information so when some condition occurs (e.g. the context elements have changed) you receive a notification [5].
One more fruitful meeting with the Z-Bre4k consortium. The mains topics where, ML, software integration and the extended usage of the Fiware Orion Broker (an article is coming about this).
In the past ten years, the word IoT (Internet of Things) has become more and more popular. But, what exactly is IoT? Why this specific concept is so important, that is considered to be one of the main pillars of Industry 4.0?
The acronym IoT stands for Internet of Things and is mainly referred to devices, provided with a unique identifiers and the ability to transfer data over a network without requiring human intervention. In this way device become “smart” able to connect, share and interact with its user and other smart devices, while Industry 4.0 is the 4th Industrial revolution, based on the concept of automation and data exchange in manufacturing.
Sensors and smart devices
What makes the devices smart? Sensors initially! Like the human body, every stimulus is a perception through senses. The wider the perception you have, the more inclusive the information that you can give to the brain for elaboration and the more accurate the result. The brain in this case is played by AI algorithms: to elaborate information they need a lot of data.
Sensor data are thus collected and through an IoT gateway they are sent to be analysed (to the cloud or locally). The application of this concept to industrial environments in general is straightforward, and based on this, we try f having a perfect production or manufacturing line, of machines, robots and humans smoothly cooperating with each-other, to achieve maximum productivity.
In simple English, every element in the shop floor must be able to share information about its status and the task it is performing. That means that industrial machines must be equipped with sensors. The specific sensors pack depends on the machine, on the process and on the measurement’s scope, thus the first thing is to identify the parameters worth to be measured.
Typical parameters, that are usually monitored, are speed (e.g.: spindle speed for milling machines), temperature and pressure in the lubricant and cooling systems, and of course vibrations. The corresponding pack of sensors must then include encoders, thermocouples, pressure sensors and accelerometers. The generated data, together with production related information (cycletime, part produced, etc), are collected and sent through an IoT gateway using a standard communication protocol like MQTT, to data persistence systems (databases) on promises or to the cloud, for further analysis.
Extra information is collected for correlation. That information includes ambient conditions (monitored through temperature and humidity sensors) information about the produced item (analysed with video cameras, laser scanners or other sensors for non-destructive quality control analysis), data from other machines involved in the production process, including robots, but also data provided by operators through properly designed interfaces.
All those data sets feed numerical models and machine learning algorithms to predict the behavior of the machines and of the production lines with the aim of optimizing the production minimizing scarps, machine downtime and process idle times.
Difficulties in shifting to Industry 4.0
The technologies to shift to Industry 4.0 are available, and the process in principle is quite is simple: gather data, transfer data, analyze data. So why is so difficult to implement the paradigm?
Data collection: Much easier to say than to do! As it was mentioned before, everything starts from the sensors. New machines will be endowed by the required pack of sensors and will be able to directly send data to the cloud for elaboration. Although the process is still new, the shop floors are not. The ideal would be to have shop floors with I4.0 compliant machines only, but most of the shop floors are a mixture of old and new machines.
Old machines are not able to autonomously send data anywhere, but most of the times they do not even have all the required sensors on board. So, the factory stakeholders have to put extra effort by having found and installed the needed sensors. Also, there is another issue, there is no standard communication protocol! Dedicated interfaces must be created, limiting the application of “standard” IoT solution and this means that there is the need of a big investment by the companies! These investments will pay back, in the end, but not tomorrow!
Extract information from data: It is a difficult task that pays in time. In order to extract meaningful information from data, a lot of data from a long time is needed. Predictive maintenance, one of the pillars of Industry 4.0, is an example. In order to be able to generate predictions related to the machine’s components failures you need the component to fail first! But machines are designed and built in a way to minimize failures! So, a high number of machines have to been monitored for a very long time in order to have enough data to produce meaningful correlations.
People’s attitude. This covers two categories of people: decision makers and blue collar staff. The firsts are often scared by the innovation cost. Moreover, they are scared by the need of changing practices and to invest also on the staffs’ formation.
The staff, particularly the elder members, do not gladly welcome the changes, and they are scared by the idea of changing the procedures that they have applied for ages. Additionally, they are not motivated to learn new things, plus they are afraid they must change to remain a value for the company.
All those aspects lead to think that industrial revolution should be treated more as a step-by-step process than as a powerful revolution. A process in which the technical progress goes hand in hand with a change of people’s mentality, supported also by a change in communication strategies, to help the final users to see the real advantages and the real timeline of this innovation process.
IoT protocols
AMQP IoT
AMQP IoTThe Advanced Message Queuing Protocol (AMQP) is an open standard application layer protocol for message-oriented middleware. The defining features of AMQP are message orientation, queuing, routing (including point-to-point and publish-and-subscribe), reliability and security.[1]
AMQP mandates the behavior of the messaging provider and client to the extent that implementations from different vendors are interoperable, in the same way as SMTP, HTTP, FTP, etc. have created interoperable systems. Previous standardizations of middleware have happened at the API level (e.g. JMS) and were focused on standardizing programmer interaction with different middleware implementations, rather than on providing interoperability between multiple implementations. [1]
Unlike JMS, which defines an API and a set of behaviors that a messaging implementation must provide, AMQP is a wire-level protocol. A wire-level protocol is a description of the format of the data that is sent across the network as a stream of bytes. Consequently, any tool that can create and interpret messages that conform to this data format can interoperate with any other compliant tool irrespective of implementation language. [1]
CoAP
Constrained Application Protocol (CoAP) is a specialized Internet Application Protocol for constrained devices, as defined in RFC 7252. It enables those constrained devices called “nodes” to communicate with the wider Internet using similar protocols. CoAP is designed for use between devices on the same constrained network (e.g., low-power, lossy networks), between devices and general nodes on the Internet, and between devices on different constrained networks both joined by an internet. [2]
CoAP is also being used via other mechanisms, such as SMS on mobile communication networks. CoAP is a service layer protocol that is intended for use in resource-constrained internet devices, such as wireless sensor network nodes. CoAP is designed to easily translate to HTTP for simplified integration with the web, while also meeting specialized requirements such as multicast support, very low overhead, and simplicity. [2]
Multicast, low overhead, and simplicity are extremely important for Internet of Things (IoT) and Machine-to-Machine (M2M) devices, which tend to be deeply embedded and have much less memory and power supply than traditional internet devices have. Therefore, efficiency is very important. CoAP can run on most devices that support UDP or a UDP analogue. [2]
The Internet Engineering Task Force (IETF) Constrained RESTful Environments Working Group (CoRE) has done the major standardization work for this protocol. In order to make the protocol suitable to IoT and M2M applications, various new functionalities have been added. The core of the protocol is specified in RFC 7252; important extensions are in various stages of the standardization process. [2]
Data Distribution Service (DDS)
The Data Distribution Service (DDS) for real-time systems is an Object Management Group (OMG) machine-to-machine (sometimes called middleware or connectivity framework) standard that aims to enable dependable, high-performance, interoperable, real-time, scalable data exchanges using a publish–subscribe pattern. DDS addresses the needs of applications like aerospace and defense, air-traffic control, autonomous vehicles, medical devices, robotics, power generation, simulation and testing, smart grid management, transportation systems, and other applications that require real-time data exchange. [3]
DDS is networking middle ware that simplifies complex network programming. It implements a publish–subscribe pattern for sending and receiving data, events, and commands among the nodes. Nodes that produce information (publishers) create “topics” (e.g., temperature, location, pressure) and publish “samples”. [3]
DDS delivers the samples to subscribers that declare an interest in that topic. DDS handles transfer chores: message addressing, data marshalling and demarshalling (so subscribers can be on different platforms from the publisher), delivery, flow control, retries, etc. Any node can be a publisher, subscriber, or both simultaneously. The DDS publish-subscribe model virtually eliminates complex network programming for distributed applications. [3]
EnOcean
The EnOcean technology is an energy harvesting wireless technology used primarily in building automation systems, and is also applied to other applications in industry, transportation, logistics and smart homes. The frequency of EnOcean IoT Protocol is 315 MHZ, 868 MHz and 902MHz. It provides you access in Cloud, and the range it covers is 300m outdoors and 30m indoors. Modules based on EnOcean technology combine micro energy converters with ultra low power electronics, and enable wireless communications between battery less wireless sensors, switches, controllers and gateways. [4]
In March 2012, the EnOcean wireless standard was ratified as the international standard ISO/IEC 14543-3-10. The standard covers the OSI (Open Systems Interconnection) layers 1-3 which are the physical, data link and networking layers. The energy harvesting wireless modules are manufactured and marketed by the company EnOcean which is based in Oberhaching, Germany. EnOcean offers its technology and licenses for the patented features within the EnOcean Alliance framework. [4]
LoRaWAN
LoRa (Long Range) is a spread spectrum modulation technique derived from chirp spread spectrum (CSS) technology and is the first low-cost implementation of chirp spread spectrum for commercial usage. It was developed by Cycleo of Grenoble, France, and acquired by Semtech in 2012, a founding member of the LoRa Alliance.[5]
Semtech’s LoRa devices and wireless radio frequency technology (LoRa Technology) is a long range, low power wireless chipset that is used in a lot of Internet of Things (IoT) networks worldwide. LoRa Technology enables a variety of smart IoT applications aimed at solving challenges like energy management, natural resource reduction, pollution control, infrastructure efficiency, disaster prevention, and more. LoRa is a long-range wireless communication protocol that competes against other low-power wide-area network (LPWAN) wireless such as narrowband IoT (NB IoT), the Wize technology, Sigfox or LTE Cat M1. [5]
MQTT
MQTT (Message Queuing Telemetry Transport) is an ISO standard (ISO/IEC PRF 20922) publish-subscribe-based messaging protocol. It works on top of the TCP/IP protocol suite. It is designed for connections with remote locations where a “small code footprint” is required or the network bandwidth is limited. The publish-subscribe messaging pattern requires a message broker. Alternative message-oriented middleware includes the Advanced Message Queuing Protocol (AMQP), Streaming Text Oriented Messaging Protocol (STOMP), the IETF Constrained Application Protocol, XMPP, DDS, OPC UA, and Web Application Messaging Protocol (WAMP). [6]
RFID
Radio-frequency identification (RFID) uses electromagnetic fields to automatically identify and track tags attached to objects. The tags contain electronically stored information. Passive tags collect energy from a nearby RFID reader’s interrogating radio waves. Active tags have a local power source (such as a battery) and may operate hundreds of meters from the RFID reader. Unlike a barcode, the tags don’t need to be within the line of sight of the reader, so it may be embedded in the tracked object. RFID is one method of automatic identification and data capture (AIDC). [7]
RFID tags are used in many industries. For example, an RFID tag attached to an automobile during production can be used to track its progress through the assembly line; RFID-tagged pharmaceuticals can be tracked through warehouses; and implanting RFID microchips in livestock and pets enables positive identification of animals. [7]
Since RFID tags can be attached to cash, clothing, and possessions, or implanted in animals and people, the possibility of reading personally-linked information without consent has raised serious privacy concerns. These concerns resulted in standard specifications development addressing privacy and security issues. ISO/IEC 18000 and ISO/IEC 29167 use on-chip cryptography methods for untraceability, tag and reader authentication, and over-the-air privacy. ISO/IEC 20248 specifies a digital signature data structure for RFID and barcodes providing data, source and read method authenticity. This work is done within ISO/IEC JTC 1/SC 31 Automatic identification and data capture techniques. Tags can also be used in shops to expedite checkout, and to prevent theft by customers and employees. [7]
In 2014, the world RFID market was worth US$8.89 billion, up from US$7.77 billion in 2013 and US$6.96 billion in 2012. This figure includes tags, readers, and software/services for RFID cards, labels, fobs, and all other form factors. The market value is expected to rise to US$18.68 billion by 2026. [7]
Sigfox
Sigfox is a French global network operator founded in 2009 that builds wireless networks to connect low-power objects such as electricity meters and smartwatches, which need to be continuously on and emitting small amounts of data. [8]
Sigfox employs the differential binary phase-shift keying (DBPSK) and the Gaussian frequency shift keying (GFSK) that enables communication using the Industrial, Scientific and Medical ISM radio band which uses 868MHz in Europe and 902MHz in the US. [8]
It utilizes a wide-reaching signal that passes freely through solid objects, called “Ultra Narrowband” and requires little energy, being termed “Low-power Wide-area network (LPWAN)”. The network is based on one-hop star topology and requires a mobile operator to carry the generated traffic. [8]
The signal can also be used to easily cover large areas and to reach underground objects. As of October 2018, the Sigfox IoT network has covered a total of 4.2 million square kilometers in a total of 50 countries and is on track to reach 60 countries by the end of 2018. [8]
Sigfox has partnered with a number of firms in the LPWAN industry such as Texas Instruments, Silicon Labs and ON Semiconductor. The ISM radio bands support limited bidirectional communication. [8]
Thread
Thread is an IPv6-based, low-power mesh networking technology for IoT products, intended to be secure and future-proof. The Thread protocol specification is available at no cost, however this requires agreement and continued adherence to an EULA which states that “Membership in Thread Group is necessary to implement, practice, and ship Thread technology and Thread Group specifications.” Membership of the Thread Group is subject to an annual membership fee except for the “Academic” tier. [9]
In July 2014, the “Thread Group” alliance was announced, which is a working group with the companies Nest Labs (a subsidiary of Alphabet/Google), Samsung, ARM Holdings, Qualcomm, NXP Semiconductors/Freescale, Silicon Labs, Big Ass Solutions, Somfy, OSRAM, Tyco International, and the lock company Yale in an attempt to have Thread become the industry standard by providing Thread certification for products. In August 2018 Apple joined the group raising hopes it will help popularize the protocol.[9]
Thread uses 6LoWPAN, which in turn uses the IEEE 802.15.4 wireless protocol with mesh communication, as does Zigbee and other systems. Thread however is IP-addressable, with cloud access and AES encryption. A BSD licensed open-source implementation of Thread (called “OpenThread”) has also been released by Nest.[9]
WiFi
Wi-Fi is a family of radio technologies commonly used for wireless local area networking (WLAN) of devices. It is based on the IEEE 802.11 family of standards. The Wi-Fi Alliance includes 3Com (now owned by HPE/Hewlett-Packard Enterprise), Aironet (now owned by Cisco), Harris Semiconductor (now owned by Intersil), Lucent (now owned by Nokia), Nokia and Symbol Technologies (now owned by Zebra Technologies). [10]
Wi-Fi uses multiple parts of the IEEE 802 protocol family and is designed to seamlessly interwork with its wired sister protocol Ethernet. Devices that can use Wi-Fi technologies include desktops and laptops, smartphones and tablets, smart TVs, printers, digital audio players, digital cameras, cars and drones. Compatible devices can connect to each other over Wi-Fi through a wireless access point as well as to connected Ethernet devices and may use it to access the Internet. Such an access point (or hotspot) has a range of about 20 meters (66 feet) indoors and a greater range outdoors. Hotspot coverage can be as small as a single room with walls that block radio waves, or as large as many square kilometres achieved by using overlapping access points. [10]
The different versions of Wi-Fi are specified by various IEEE 802.11 protocol standards, with the different radio technologies determining the ranges, radio bands, and speeds that may be achieved. Wi-Fi most commonly uses the 2.4 gigahertz (12 cm) UHF and 5 gigahertz (6 cm) SHF ISM radio bands; these bands are subdivided into multiple channels. Each channel can be time-shared by multiple networks. These wavelengths work best for line-of-sight. Many common materials absorb or reflect them, which further restricts range, but can tend to help minimize interference between different networks in crowded environments. At close range, some versions of Wi-Fi, running on suitable hardware, can achieve speeds of over 1 Gbit/s (Gigabit per second). [10]
ZigBee
The name refers to the waggle dance of honey bees after their return to the beehive. Zigbee is an IEEE 802.15.4-based specification for a suite of high-level communication protocols used to create personal area networks with small, low-power digital radios, such as for home automation, medical device data collection, and other low-power low-bandwidth needs, designed for small scale projects which need wireless connection. Hence, Zigbee is a low-power, low data rate, and close proximity (i.e., personal area) wireless ad hoc network. [11]
The technology defined by the Zigbee specification is intended to be simpler and less expensive than other wireless personal area networks (WPANs), such as Bluetooth or more general wireless networking such as Wi-Fi. Applications include wireless light switches, home energy monitors, traffic management systems, and other consumer and industrial equipment that requires short-range low-rate wireless data transfer. [11]
Its low power consumption limits transmission distances to 10–100 meters line-of-sight, depending on power output and environmental characteristics. Zigbee devices can transmit data over long distances by passing data through a mesh network of intermediate devices to reach more distant ones. [11]
Zigbee is typically used in low data rate applications that require long battery life and secure networking (Zigbee networks are secured by 128 bit symmetric encryption keys.) Zigbee has a defined rate of 250 kbit/s, best suited for intermittent data transmissions from a sensor or input device. [11]
Z-Wave
Z-Wave is a wireless communications protocol used primarily for home automation. It is a mesh network using low-energy radio waves to communicate from appliance to appliance, allowing for wireless control of residential appliances and other devices, such as lighting control, security systems, thermostats, windows, locks, swimming pools and garage door openers. [12]
Like other protocols and systems aimed at the home and office automation market, a Z-Wave system can be controlled via the Internet from a smart phone, tablet or computer, and locally through a smart speaker, wireless key fob, or wall-mounted panel with a Z-Wave gateway or central control device serving as both the hub controller and portal to the outside. Z-Wave provides the application layer interoperability between home control systems of different manufacturers that are a part of its alliance. [12]
The frequency of Z-Wave Internet of Things Protocols is 900MHz, and the range is about 30-100m. It provides you Cloud access and requires a bridge for it. Data rates of this protocol are 40-100kbit/s
Bonus : Bluetooth
Bluetooth is a wireless technology standard for exchanging data between fixed and mobile devices over short distances using short-wavelength UHF radio waves in the industrial, scientific and medical radio bands, from 2.400 to 2.485 GHz, and building personal area networks (PANs). [13]
It was originally conceived as a wireless alternative to RS-232 data cables. Bluetooth is managed by the Bluetooth Special Interest Group (SIG), which has more than 35,000 member companies in the areas of telecommunication, computing, networking, and consumer electronics. The IEEE standardized Bluetooth as IEEE 802.15.1, but no longer maintains the standard. The Bluetooth SIG oversees development of the specification, manages the qualification program, and protects the trademarks. [13]
A manufacturer must meet Bluetooth SIG standards to market it as a Bluetooth device. A network of patents apply to the technology, which are licensed to individual qualifying devices. [13]
The Industry 4.0 future aims the machines to be able of self-diagnostics to avoid failures, optimized production to avoid defects, minimized idle time thanks to the communication among different production process actors, including robots, workers with wearable devices that simplify their tasks and with shifts organized to maximize well being (and thus productivity) thanks to information collected by bio-sensors.
* This article joint effort between Alice Reina (here and here) and me.
Alice Reina graduated in Aerospace Engineering at Politecnico di Milano (Italy) where she obtained also a PhD in Aerospace Engineering with a dissertation on nanocomposites for space applications. She worked 5 years as a researcher at the Space Propulsion Laboratory of the Politecnico di Milano dealing with advanced material for solid rocket motors and hybrid rocket engines.
Then, she moved to the private sector, applying the experience gained in R&D projects development to advanced manufacturing, managing research and innovation projects and proposals in different fields (Industry 4.0, Circular economy, additive/hybrid manufacturing, composite manufacturing, robotics, space). She now works for Avio S.p.A where she covered the role of research programs manager and proposal developer, where she collaborates to the innovation in space transportation systems.
I don’t throw darts at a board. I bet on sure things. Read Sun Tzu, ‘The Art of War.’ Every war is won before it is ever fought
Gordon Gekko – Wallstreet (1987) Image from Letterboxd
Introduction
Let’s assume you are hired to develop a software system for a pharmaceutical company. Till that time, you knew nothing about that specific domain, no more than everybody knows about the pharmaceutical sector and medicines.And the knowledge you carry is from the side of the patient-client.
You start gathering information to build the requirements, but you come to point that you feel ready to start writing code. Well, don’t hurry that much. Are you sure the information you have in your hands is right, and at the same time is the one you actually need?
Lack of domain expertise
Programmers, unfortunately, sometimes change domains a lot. Take for example! I was working for a company that develops HR and payroll software, and now I work for European funded R&D projects related to Industry 4.0. Far from similar. But no matter what I have to adapt, to learn and be productive as fast as possible.
In the agile world, the product owner represents a range of stakeholders, not just end users, and in practice it isn’t reasonable to expect them to be experts at everything in the domain. As a result the product owner will bring in domain experts to work with the team. The programmers responsibility is to be open minded and learn from every word information that comes from the expert. Also don’t be a “know all” person. Trust the domain expert and work with them.
Understanding the domain helps you design a better software. A software with the expected, by the stakeholders, behavior as the stakeholders and not assumptions.
The pharmaceutical example
The moment comes that you have to create a class for medicines. What you will take under consideration for the fields (state) and the methods (behavior) of the class? Most medicines come in a variety of types or formats. The types of medicines are the following:
Liquid
Tablet
Capsules
Topical medicines
Suppositories
Drops
Inhalers
Injections
Implants or patches
Buccal or sublingual tablets or liquids
Have you been aware of that? Probably you knew some of them… but we need all of them, cause this is what the pharmaceutical company asked for! Are we done? Far from there! We still have to decide about the the methods of the class. Methods denote actions. A medicine what kind of actions does it carry? The “every X hours” frequency action is part of the Medicine class or the Prescription class? Of course is part of the Prescription class! But I believe that all of us agree, that some programmer would do that mistake. I could carry with many more examples, but I am confident that you got the point.
What if… there is no domain expert?
Well, if I were you, I wouldn’t accept the role, of let them hire me. In the past two years, I wouldn’t be able to develop software that matters with the support of the domain experts (electrical, mechanical and chemical engineers). It’s not easy to model a problem without the concrete knowledge of the domain.
Additionally, the domain expert has to have a basic IT knowledge. It is, at least unacceptable, to work with people who do not understand the basics of how a computer or a software system works. And believe me, there are a lot of them!
Conclusions
A piece of advice. All domains, no matter how easy or boring might seem in the beginning, they all carry knowledge and history. Understanding the domain, doesn’t just make you a better programmer, but it helps you understand how things work in a more insightful way. You become a better citizen in the end.
This is our world now. The world of the electron and the switch; the beauty of the baud. We exist without nationality, skin color, or religious bias. You wage wars, murder, cheat, lie to us and try to make us believe it’s for our own good, yet we’re the criminals. Yes, I am a criminal. My crime is that of curiosity. I am a hacker, and this is my manifesto.” Huh? Right? Manifesto? “You may stop me, but you can’t stop us all.
Static method and classes are one of the OOP world’s drawbacks. I am not implying that you shouldn’t use it at all, but in long term I believe a source code full of static methods and classes add more burden into the maintenance process.
How does static code look like?
Worker methods. Good for Simple calculations / processing, i.e b MyUtilityClass.ConvertAtoB(a)
Factory methods. Used to return preconfigured instances of a class, i.e. MyClass MyClass.GetInstanceOfClass()**
Singleton methods. Used to enforce a single global instance of a class, i.e. MyClass MyClass.SharedInstance()
Global variables. Used to store configuration values, i.e. int MyClass.TimeoutDuration
** Do not confuse it with Factory design pattern!
Why do we prefer the easy way out?
Suppose we have two classes A and B, and have a method M() that both must use, then the most naive approach is to repeat the method in both classes. However, this violates the “Don’t repeat yourself” (DRY) approach. It’s not just about reducing work: if both classes truly need the same method, then it should be the same method.
The most natural solution is inheritance, but it’s not always beneficial for A and B to be sub classes of some parent class. The bad and easy alternative is to define a “Utility” class: a public static class that sits in the global namespace, awaiting anyone to “borrow” them.
Static classes and methods imply relationships between data that are not explicitly defined. Also, if the static classes have any static variables, then A and B have no idea which object called them.
Where do static methods belong?
A class in OOP has state. When we look at our classes from the Single Responsibility Principle (SRP) viewpoint, a static method is usually a violation because it tends to have a responsibility that is not the same of the class it is attached on. So it ends up sitting out there trying to belong to the class it is on, but it doesn’t really belong, because it doesn’t use the internal state of the class.
Furthermore, based again on SRP, a class should have one and only one reason to change. But if we end up designing huge utility classes that contain any method the developer could think of, (e.g. a class containing a helper method for URL encoding, a method for looking up a password, and a method for writing an update to the config file) this is crystal clear violation of the Single Responsibility Principle.
Static methods and the rest of S.O.L.I.D.
Liskov Substitution Principle. Derived classes must be substitut-able for their base classes — If a class has only static methods , can not have a derived class. Maybe it’s not a direct violation, but every time we loose, we loose more and more destroying the project’s architecture.
Interface Segregation Principle. Class interfaces should be fine-grained and client specific. Since static classes do not derive from an interface, it is difficult to apply this principle with any degree of separation from the Single Responsibility Principle.
The Open Closed Principle. Classes should be open for extension and closed for modification. We cannot extend a helper class. Since all methods are static, we cannot derive anything that extends from it. In addition, the code that uses it doesn’t create an object, so there is no way to create a child object that modifies any of the algorithms in a helper class.
They are all “unchangable”. As such, a helper class simply fails to provide one of the key aspects of object oriented design: the ability for the original developer to create a general answer, and for another developer to extend it, change it, make it more applicable. If we assume that we do not know everything, and that we may not be creating the “perfect” class for every person, then helper classes will be an anathema to we .
The Dependency Inversion Principle. Depend on abstractions, not concrete implementations. This is a simple and powerful principle that produces more testable code and better systems. If we minimize the coupling between a class and the classes that it depends upon, we produce code that can be used more flexibly, and reused more easily.
With static classes/methods we have a clear violation of DIP. A class like that, cannot participate in the Dependency Inversion Principle. It cannot derive from an interface, nor implement a base class. No one creates an object that can be extended with a static class.
Static code and architecture
What is inside static methods? Well no one knows, and that is the problem. Static code must not keep inside it any meaningful state to the project . It should only carry out calculations statements like Math.Abs(), or String.ToUppercase(). We give an input, it works on that, generates the output. That’s it!
But unfortunately, reality is different. People always want more, and end up hurting their projects. Static methods might end up being huge, with complex code in them, with state, and sometimes create and manipulate objects, thus the complexity of the application is increased. The more static methods there are, the more a programmer working in the application has to know where is what and what’s in there. And this is only part of the problem.
Another part is naming static classes and methods. A static method with the name CalculateHolidays which calendar satisfies? Gregorian you will say!And you are right… most of the times! But there are seven calendars in regular current use around the world.
They are the following:
The Gregorian (Is used worldwide for business and legal reasons)
The Chinese (The Chinese calendar is not used in China but is used in various countries of south east Asia, usually with local variations. For example the calendar used in Japan is a variation of the Chinese one. It is also used socially by ethnic Chinese around the world.)
The Hebrew (The Hebrew calendar is used, of course, in Israel, as well as by Jews around the world for their religious observances)
The Islamic (is used by Muslims around the world for setting the dates of religious celebrations)
The Persian (Iran and Afghanistan)
The Ethiopian (Ethiopia)
The Balinese Pawukon (Bali).
So 7 static methods with the appropriate names might one say ! Wrong! We have enums, factory design pattern, we can’t just drop all of them away and being lazy. Plus, renaming or replacing the class containing static methods necessarily requires refactoring all references to it.
Another issue we must address is memory management. Referring to a static class, the class itself is guaranteed to be loaded and have all of the necessary fields inside instantiated before it is ever referenced with the code. Its constructor will only be called a single time.So, this class and methods will remain in memory for the lifetime of the application’s domain.
Static code and unit testing
Unit testing assumes that we can instantiate a piece of the application in isolation. During the instantiation we replace any dependencies with mocks/fakes/stubs. We prevent the execution of the normal code path and is how we achieve isolation of the class under test. With static code we can’t away from the normal path, we can’t replace the static code, because there are no objects to replace.
Also, sometimes static methods is a factory for creating other objects. In tests we rely on the fact replacing important dependencies with mocks. A caller of such a static factory is permanently bound to the concrete classes which the static factory method produced.
In unit testing, we intent to test the monkey and how it eats the banana. With the static code, we are forced to add in the act, the tree the monkey sits on, the plantains the banana grew, and even worse the jungle itself. In the end, this is not unit testing…
The solution?
Maybe the solution is interfaces! Composition or aggregation of objects over inheritance! Both of them are fairly easy to understand, we can see composition in everyday life: a chair has legs, a wall is composed of bricks and mortar, and so on.
Inheritance is more of an abstraction. Though it is possible to mimic inheritance using composition in many situations, it is often unwieldy to do so. The purpose of composition is obvious: make wholes out of parts. The purpose of inheritance is a bit more complex because inheritance serves two purposes, semantics and mechanics.
Inheritance captures semantics (meaning) in a classification hierarchy (a taxonomy), arranging concepts from generalized to specialized, grouping related concepts in sub trees, and so on. The semantics of a class are mostly captured in its interface, the set of messages to which it responds, but a portion of the semantics also resides in the set of messages that the class sends.
When inheriting from a class, we are accepting responsibility for all of the messages that the super class sends on our behalf, not just the messages that it can receive. This makes the subclass more tightly coupled to its super class than it would be if it merely used an instance of the super class as a component instead of inheriting from it. Note that even in classes that don’t “do” much, the name of the class imparts significant semantic information about the domain to the developer.
Inheritance captures mechanics by encoding the representation of the data/state (fields) and behavior (methods) of a class and making it available for reuse and augmentation in sub classes. Mechanically, the subclass will inherit the implementation of the super class and thus also its interface.
The dual purpose of inheritance can cause more confusion. Many people think that “code reuse” is the primary purpose of inheritance, but that is not its only purpose. An overemphasis on reuse can lead to tragically flawed designs.
Business people are completely different than us. Their point of view is sometimes so far away from ours, that in the end, there might be no overlap at all. Every domain has its own principles, its own constants, and that’s why we must setup a common ground, in order to achieve productive communication and it the end quality software.
My truth, your truth
Before setting up any principles with people different than you, the first step to identify their truth, their principles that lead them to design/build/work. For business people those pillars are for sure two: time and money. Yes, those two! Of course there are more, but but the last square will always be those two. Do you know what programmers hate? Deadlines (time)! Although this sound totally against the every day’s life of a programmer, it is true. And the reason is simple. We are craftsmen, not a factory’s production line. And as craftsmen we have one principal, a principal to rule all the others in software development, and this one is software quality. If your house constructor needs more time to finish building you will him all the time he asked, even under pressure. I am sure, no one of us would live to an half built home.
Communication breakdown!*
So what is wrong? What happens and we deliver bad software? We can’t blame the tech stacks any more. We have powerful languages, libraries, cloud, tasks automation, experience and knowledge to solve almost any known problem in the business world (AI is still on the go). So what is left to check? What is always has been the problem! People!
Businesses do not always define IT services. It’s more a perception question than a size one. And after one is defined, someone has to explain to the IT guys what to do. In all of cases, the IT department has not a clear view of what the business does, and is unaware of the business priorities. A lot of business people, consider the IT department as a black box. They don’t care how they work, they just expect the final result (software) and clients happy! Well, software development is not a vending machine!
On the other hand, the IT department needs to know what the company does. Let’s take under consideration the following example: A company named iBuildBuildings is mixing cement. The cement takes less than an hour to harden once it’s mixed, and it has to get where it’s going before that. A client called in because he was having trouble dispatching the truck and the IT guy says, “I’m going to lunch. I’ll deal with it when I get back.” That’s showing he didn’t understand that it hardens.
No matter how good your software is, or if the server was 100% up all year long, the cement guy doesn’t care about that. Well he should, but in that specific moment, the problem, was not the bug in the software, bug the IT guy who didn’t care about the business needs.
I am IT, can I contribute to business?
A lot of business decisions are made upon IT feedback. Is this good or bad? It depends. If everybody knows their places, their responsibilities, their goals, their limits, the business needs, then probably is good. If not, then we have communication breakdown.
When an IT guy talks to a business one, he has to speak in terms of money and time, not in technical terms.
For example:
A small deliver company that is called iDeliverEverythingAndEverywher wanted to update their smartphones. If the IT department is trying to contribute by talking on smartphone CPU speed, version, OS it will achieve nothing. It has to speak in business terms. To explain that the new smartphones can handle GPS better, and will speed up deliveries.
A lot of times, the IT guys make things more complex and tend to cause more problems in the business, than they solve.
Time is killing software quality, for the sake of money
Everyday thousands, maybe millions, decisions are made in the is fashion. But let’s set the record straight here. Any software that is developed with the wrong people, with less people, with ambiguous or half described requirements, underfunded and with time pressure is gonna suck big time. An application of that kind doesn’t create problems only at the moment, but for the future times to come, by generating a technical debt.
For a company that doesn’t have a lot of time, money or people, any decisions on software implementation must be extremely lean. No one can afford to waste a huge amount of time and money, thinking about processes that give no value to the business or to the clients.
If it is not clear, what the process does and what will offer to the business value, there is no time wasting on thinking about that. Also half solutions must be avoided. They are worst than taking no decisions at all.
Only the processes that are going to have a measurable impact matter. Once the strategy is laid out, you can understand the process, you can see what needs to be worked on.
That is way software development must NOT be a black box for business people. Time and money are wasted on wrong decisions that were meant to be right.
In the end what really matters is to initially understand what is the problem that needs be solved? But processes have not value if the principles are not defined. All parts must contribute, but on the same principles. The goal view must be same and must not deviates influenced by the department you come from.
The more you know who you are and what you want, the less you let things upset you.
Bob Harris – Lost in translation (2003) Image from FocusFeatures
Introduction
For the past, almost, two years, I have been working in H2020 EU projects. In simple terms this means that I participate in consortiums with partners from all around the European Union, so I have to use my English language skills almost every day.
My mother tongue is Greek, so my English is not perfect. But I try, and I try a lot my speaking and my writing to be as correct as possible. I try to improve daily as much as possible, and the reason is simple: I am a professional, and there is no room for excuses!
Usual excuses
Lack of opportunities to practice English.You can watch a movie, read a book, or find people online to practice it!
Lack of time. This is the biggest excuse ever! Instead of using the Spanish or Italian or whatever translations of a technical manual, use the English version. Grammar, vocabulary, terminology are all in there.
Not understanding everything. Well, you understand some or a lot!, So engage into the conversation, make mistakes and improve your English language skills!
No one corrects me. Besides the fact that you can find a tutor to support you, practicing and checking now and then a grammar and a vocabulary book will actually help you a lot you to make less mistakes.
The impact
Not improving your English language lead to bad professional impact. It’s not that it makes it more difficult to communicate with your current partners, but keeps you away from the labor market, at least the part of it you are interested in.
I could write down at least three to four examples, of failed communications cause the other party didn’t speak English. And those incidents didn’t occur to a small local city but in the center of Brussels!
And to be totally honest, English is not enough anymore. Speaking languages like German, Chinese, Russian, Spanish is a huge advantage. And the reason for learning those languages is simple: Those languages are spoken to many countries that are markets to services and products provided by the companies you probably want to work for.
Conclusions
Don’t keep yourself out the IT industry, or any industry. English is nowadays part of the basic skills, not the extras. Even I, at the age of the 36 I am planning to take German language courses.
Rachael – Blade Runner movie (1982) Image frame from the “Blade Runner” movie (1982)
Introduction
Programmers are people, not aliens. Well maybe not the most social ones, but still people. They carry their own personalities, emotions, culture, and set priorities based on their interests, as everybody else! Why programmers should be the exception? The reason is simple: Programmers work in teams by default, even if it seems otherwise!
They are always part of a team, even if that team is consisted by the sole programmer and the client. Programmers, at least, always need a domain expert who might be a colleague, a supervisor, the client, the product owner of someone else.Of course, those kind of teams are not (always) efficient but sometimes this is all we might get.
The key issue is that programmers are trained to be programmers, but they are not culturally educated to work as team members, nor in universities, nor when in business line. We prefer to work alone, with minimum distractions, we avoid meetings like vampires the garlic, and assembling a team of programmers for a project is not an easy task, at all.
Not everybody want to participate to a team, at least quite actively, and sometimes they might not like their teammates for numerous reasons. So in the end, what we have are programmers as units addressed as a team, and those units only care to make their boss happy, or themselves. Additionally, what happens when we set a team of junior and senior programmers? Without the right principles and processes, that team is going to collapse in no time!
The bad programmer
All the bad programmer types below, that you have read about them again and again, are based on bad attitude, not lack of skills.
Don’t just copy paste code. Copy pasting itself is not bad. Not knowing what this code does, and why is bad! If you are not aware of the consequences don’t paste till you are sure.
Dirty code. Don’t just write code that works. Write code that is understandable by others, and by yourself after some time. Follow a variables naming guideline, indentation, coding style, avoid fat objects etc (clean code is going to be an article in the future).
Don’t avoid testing. Avoid testing is not bad for the project itself, it is mainly bad for your and your colleagues. Testing help us reduce technical debt, fix unpredictable code, remove useless or/and old code if it exists, help us keep things under control.
Learn the domain.: Focus and learn the domain you are working on, don’t just develop a feature or fix a bug. Knowing the domain help us write better code, develop the expected, by the clients, behaviour of the system, and utilise this knowledge in the future. Programming without understanding the domain is like shooting in the dark.
The rigid programmer. Always learn new languages, new frameworks if needed. Don’t feel side if you have to program using another language. Try leaving your comfort zone, and embrace something new!
The super wow solution. Complicates problems ask for simple solutions. Over-engineered and complex code works for a short time and crashes after a while. This adds to the technical debt, and the later the debt it handled, the worse!
The not case! How many times we have heard by our colleagues, or even by ourselves the following phrases: “I did’t write this”, “It is not my problem”, “It is not my fault, it is X’s fault ” “I can’t (don’t want to) fix it”. Negative attitude leads to negative responses, so be careful.
The wanna be hero. Huge ego is bad for the team. If you are the best and most experienced programmer in the team, do not enforce your personality or ideas to others. On the contrary, teach them, guide them, give them a change to listen and understand you. It’s not your project, it’s the team’s, and the company’s, project. Huge ego is equal to low productivity.
Avoiding documentation. Clean code is a must. But sometimes extra comments or documentation are needed. Especially, besides the technical details you have to describe the domain details to add value to the provided solution. Do not forget that one day you might leave the company. What you will leave be behind must be clean, transparent, well described and detailed.
Programmers soft skills
Again, programmers are people as everybody else. And every professional who respect themselves, their colleagues, their bosses, the companies they work for, they must be honest, open minded and modest, they must listen but not speak, share and not keeping to themselves, understanding, supporting and not judging are skills that are needed. Programmers, unfortunately tend to fight like artists. Who is the best artist, whose methodology overrule the others, whose work is most important? No matter if a programmer works as a freelancer, or for a company the concept is the same. You have to play nice, by the rules and with others. Unfortunately, reality is different. Not all programmers have a business culture, nor companies either.
So how do you build a culture? First of all this is perpetual process, and doesn’t complete after a specific period of time. Be honest to yourself and to others and open minded. Read books, watch talks on YouTube.No programmer is perfect, nor in skills, nor in personality.
Always try to work for companies with transparent, crystal clear culture. It’s the best feeling to know since day one what is your role, your responsibilities, your limits, the etiquette, with whom you will work with and why. If things are always blur, or change all the time then quit and find a new job! A long as you allow yourself into a rotten environment, in the end you will rot also.
Conclusions
Unfortunately, a lot of programmers and companies are ignorant and selfish. They think they know something when they don’t, or they have no idea that there is something more to know. This mentality leads to poor project results and in toxic relationships. Many software companies, don’t attempt to improve their employees, their principles, their processes and lot of programmers aren’t willing to improve themselves.
Feeling flexible and taking liberties at work is good, but if the company doesn’t align back you back to the company’s philosophy and principles if you diverge, that both you and the company are not disciplined.
Functional programming is how programming should be. We want behaviours (functionalities), that receive an input and produce an output. Simple as that. Of course we might need to process again and again the data in hand, but this is also part of the expected behaviour: one’s function output is the other one’s input.
The ultimate goal is to deliver a software product built with reliable code, and the best way to do that is simplicity. Therefore programmers’ main responsibility is to to reduce code complexity. The whole picture is that OOP doesn’t deliver as excepted, nor in code quality nor in deadlines. It looks good in diagrams, but once the complexity starts increasing ,things, slower or faster, are getting out of hand. Especially when the state is mutable and shared, then a chaos is on the loose. Even full test coverage worth nothing, if the source code is complex and not maintainable.
In the seventies, the idea of “real OOP” was hugely powerful, but what was implemented was far from a complete set of ideas, especially with regard to scaling, networking, etc. How dynamic objects intertwined with ontologies and inference was explored by Goldstein and Bobrow at Parc. Their four papers on PIE and their implementation were the best extensions ever done to Smalltalk, and two of the ideas transcended the Smalltalk structure and deserved to be the start of a new language, and perhaps have a new term coined for it.
Alan Kay’s original idea about OOP
The term “Object Oriented Programming” was first coined in 1996 by Alan Kay. Based on his answers in 2003, via email Stefan Ram’s (a German computer science professor in Berlin at that time), his ideas on OOP were completely different from what we have today in our hands as OOP languages.
At Utah sometime after Nov 66 when, influenced by Sketchpad, Simula, the design for the ARPAnet, the Burroughs B5000, and my background in Biology and Mathematics, I thought of an architecture for programming. It was probably in 1967 when someone asked me what I was doing, and I said: “It’s object-oriented programming”.
– I thought of objects being like biological cells and/or individual computers on a network, only able to communicate with messages (so messaging came at the very beginning – it took a while to see how to do messaging in a programming language efficiently enough to be useful).
– I wanted to get rid of data. I realized that the cell/whole-computer metaphor would get rid of data, and that “<-” would be just another message token (it took me quite a while to think this out because I really thought of all these symbols as names for functions and procedures.
– My math background made me realize that each object could have several algebras associated with it, and there could be families of these, and that these would be very very useful.
Alan Kay answering to Paul Ram in 2003
So far, based on Alan Kay’s answers, he focuses on cells (objects) exchanging messages to each other. His true goal was messaging.
The term “polymorphism” was imposed much later (I think by Peter Wegner) and it isn’t quite valid, since it really comes from the nomenclature of functions, and I wanted quite a bit more than functions. I made up a term “genericity” for dealing with generic behaviors in a quasi-algebraic form. […]
OOP to me means only messaging, local retention and protection and hiding of state-process, and extreme late-binding of all things. It can be done in Smalltalk and in LISP. There are possibly other systems in which this is possible, but I’m not aware of them.
Alan Kay answering to Paul Ram in 2003
Inheritance and polymorphism are not even mentioned! In the end, according to Alan Kay, the three pillars of OOP are:
Message passing
Encapsulation
Dynamic binding
Combining message passing and encapsulation we try to achieve the following:
Stop sharing mutable state among objects, by encapsulating it and allow only local state changes. State changes are at a local, cellular level rather than exposed to shared access.
A messaging API is the only way the objects communicate. Thus the objects are decoupled. The messages sender is loosely or not coupled at all to the message receiver.
Resilience and adaptability to changes at runtime via late binding.
[…] the whole point of OOP is not to have to worry about what is inside an object. Objects made on different machines and with different languages should be able to talk to each other […]
Alan Kay – The Early History Of Smalltalk
This sentence actually is talking about distributed and concurrent systems. Objects hide their states from each other and they just communicate (“talk to each other”) by exchanging messages. In simple words, objects should be able to broadcast that they did things (changed their state actually) and the other objects can ignore them or respond. This concept reminds of agents modelling or even actors. The key point that can improve the isolation among objects, is that the receiver is free to ignore any messages it doesn’t understand or care about.
Finally, let’s remember one more of Alan Kay’s quotes
I made up the term object-oriented, and I can tell you I did not have C++ in mind.
Alan Kay
It was in the eighties that “object-oriented languages” started to appear. C++ was part of a set of ideas starting around 1979 by Bjarne Stroustrup. C++ was designed to provide Simula’s facilities for program organization together with C’s efficiency and flexibility for systems programming. His approach was via “Abstract Data Types”, and this is the way “classes” in C++ are generally used. C++ was a pre-processor to C language. “Classes” were program code structuring conventions but didn’t show up as objects during run time.
Hence the quote, as Alan Kay states in Quora, which is not so much about C++ per se but about the term that we had been using to label a particular approach to program language and systems design.
OOP and human cognition
In 1995 a paper was published by Bill Curtis under the name ” Objects of Our Desire: Empirical Research on Object-Oriented Development“. Among others, there is the following sentence:
In careful experiments, Gentner (1981; Gentner & France, 1988) showed that, when people are asked to repair a simple sentence with an anomalous subject-verb combination, they almost always change the verb and leave the noun as it is, independent of their relative positions. This suggests that people take the noun (i.e. the object) as the basic reference point. Models based on objects may be superior to models based on other primitives, such as behaviours.
Objects of Our Desire: Empirical Research on Object-Oriented Development, Bill Curtis
So a paper published in the nineties cites experiments that were run in the eighties, to support OOP concept. Well, in the nineties that might made sense, based on how the software industry was at that time, but not today. Today’s software is moving towards serverless applications, which are functions as a service, rather than to complicated objects communicating to each other.
The line of business software in our times is so complex, that OOP + TDD, OOP + DDD or OOP + BDD are concepts that programmers still struggle with. What is the right number of objects? How deep the granularity of objects should be? How mutable the objects should be? What is the right architecture to follow? Although there are tons of books and articles about those issues, software projects fail, due to complexity.
Additionally Bill Curtis paper includes the following:
Miller (1991) described how nouns and verbs differ in their cognitive organizational form. Nouns – and hence the concepts associated with them – tend to be organized into hierarchically structured taxonomies, with class inclusion and part-whole relations as the most common linkages. These are also, of course, the most common relations in OO representations.
In human cognition, these hierarchies tend to be fairly deep for nouns – often six to seven layers. These hierarchies support a variety of important cognitive behaviours, including the inheritance of properties from super ordinate classes. In contrast, verbs tend to be organized in very flat and bushy structures. This again suggest a central place for objects, in that building inheritance hierarchies will mirror the way humans represent natural categories only if the basic building blocks are objects rather than processes or behaviours.
Objects of Our Desire: Empirical Research on Object-Oriented Development, Bill Curtis
So through linguistics principles, the paper supports OOP, that is objects (nouns), verbs (methods) and the hierarchy among them. But a thing missing here, is what about those programmers, whose native tongue is not English? How their brains work? Can they adapt easily, to the OOP logic or not? Even today sometimes I see variables named in other languages that English.
You will not find a single medical article that denotes that the human brain thinks, organizes, structures based on objects. We carry a “todo list”, not an “item hierarchy list”. Human brains can only hold about five items at a time in working memory. It is much easier to explain a piece of code based on what it does, rather than based on what variables change around the source code. Each language has a set or rules to constraint you, in order to speak and write correctly, it is called grammar! On the other hand in OOP programming you have so many options to solve the same problem, that in the end you can just throw any “grammar” out of the window.
Additionally, OOP code is non- deterministic. You can verify that by installing a cyclomatic complexity extension to your IDE and run it. Dependencies, null checking, type checking, conditional statements, all of them combined produce more outputs than expected. Let’s not forget Mock object in unit testing, you have to predefine its behaviour. So even if you have an a grammar, a structure of your objects, there is no guarantee that the functionalities implementation is going to be according to the grammar.
Finally, we have dependencies hell. And it”s only about nuget packages or maven dependencies. It’s the source code’s internal hierarchy. Inheritance, methods, constructors parameters, Law of Demeter, etc. So how nouns and verbs and objects hierarchy are equal to simple code without extra complexity is still a mystery.
Why Functional Programming (FP)?
Functional programming is a programming paradigm: a different way of thinking about programs than the mainstream, imperative paradigm you’re probably used to. FP is based on lambda calculus. Functions tend to provide a level of code modularity and reusability It manages nullability much better, and gives us a better way of error handling.
FP provides the following:
Power.—This simply means that you can get more done with less code. FP raises the level of abstraction, allowing you to write high-level code while freeing you from low-level technicalities that add complexity but no value.
Safety. This is especially true when dealing with concurrency. A program written in the imperative style may work well in a single-threaded implementation but cause all sorts of bugs when concurrency comes in. Functional code offers much better guarantees in concurrent scenarios cause of immutability, so it’s only natural that we’re seeing a surge of interest in FP in the era of multi core processors.
Clarity. We spend more time maintaining and consuming existing code than writing new code, so it’s important that our code be clear and intention-revealing.
So how functional a language is C#? Functions are first-class values in C#. C# had support for functions as first-class values from the earliest version of the language through the Delegate type, and the subsequent introduction of lambda expressions made the syntactic support even better. There are some quirks and limitations, but we will discuss about them in time.
Today we have LINQ. Language-Integrated Query (LINQ) is the name for a set of technologies based on the integration of query capabilities directly into the C# language. Traditionally, queries against data are expressed as simple strings without type checking at compile time or IntelliSense support. With LINQ, a query is a first-class language construct, just like classes, methods, events. You write queries against strongly typed collections of objects by using language keywords and familiar operators. The LINQ family of technologies provides a consistent query experience for objects (LINQ to Objects), relational databases (LINQ to SQL), and XML (LINQ to XML).
Query expressions are written in a declarative query syntax. By using query syntax, you can perform filtering, ordering, and grouping operations on data sources with a minimum of code. You use the same basic query expression patterns to query and transform data in SQL databases, ADO .NET Datasets, XML documents and streams, and .NET collections.
The disadvantage in the C# + FP try, is that everything is mutable by default, and the programmer has to put in a substantial amount of effort to achieve immutability. Fields and variables must explicitly be marked read-only to prevent mutation. (Compare this to F#, where variables are immutable by default and must explicitly be marked mutable to allow mutation.) Finally, collections in the framework are mutable, but a solid library of immutable collections is available.
To highlight the difference between are in OOP and FP, I provide an example: You run a company and you just decided to give all your employees a $10,000.00 raise.
OOP (imperative way)
FP
1. Create Employee class which initializes with name and salary, has a change salary instance method
2. Create instances of employees
3. Use the each method to change salary attribute of employees by +10,000
1. Create employees array, which is an array of arrays with name and corresponding salary
2. Create a change_salary function which returns a copy of a single employee with the salary field updated
3. Create a change_salaries function which maps through the employee array and delegates the calculation of the new salary to change_salary
The FP approach uses pure functions and adheres to immutability by using map With OOP, we cannot easily identify if the object has had the function called on it unless we start from the beginning and track if this has happened, whereas in FP, the object itself is now a new object, which makes it considerably easier to know what changes have been made.
FP leans heavily on methods that do one small part of a larger job, delegating the details to other methods. This combining of small methods into a larger task is composition. In our example, change_salaries has a single job: call change_salary for each employee in the employees array and return those values as a new array. change_salary also has one job: return a copy of a single employee with the salary field updated. change_salaries delegates the calculation of the new salary to change_salary, allowing change_salaries to focus entirely on handling the set of employees and change_salary to focus on updating a single employee.
Conclusions
I believe that anyone of you have understood, that the main key words are code simplicity, state immutability, messaging. From distributed mutable state around the source code (objects), to code organized by expected behaviours (functions).
FP is a programming parading as OOP is. OOP is alive and it will be for next years. But can we rely on it anymore? After 10 years as a software developer, I believe not anymore. Maybe I am wrong!
But instead of asking a better OOP language, I try to smoothly move to FP. Unfortunately I can’t completely move away from C#, due to business restrictions, but I do my best to find a better alternative.
The next episode
In the next episode, the topic is “OOP today” and an analysis about objects state.